Par Thomas JOUNEAU (Université de Lorraine, Direction de la Documentation et de l’Edition, Bibliothèque Numérique) et Thomas PORQUET (Département Services et Prospective, Consortium Couperin).
La première partie de cet article posait les questions méthodologiques liées à la manipulation des statistiques d’accès à la documentation numérique, en en listant les principaux écueils. Place maintenant aux évolutions récentes et futures, qui laissent entrevoir un peu d’espoir dans la qualification et la quantification des usages !
Évolution récente
Les constats évoqués en première partie de cet article semblent être restés valides depuis 2010 (et avant) sans évolution notable. Deux événements sont toutefois venus changer en partie la donne : la propagation d’ezPAARSE, d’une part ; la sortie de la version 5 du Code COUNTER, d’autre part.
Qualification des usages par ezPAARSE
Historique et utilité d’ezPAARSE
Logiciel libre et gratuit dont la conception développée à partir de la fin 2012 dans le cadre d’une collaboration étroite entre l’Inist-CNRS, l’Université de Lorraine et le consortium Couperin.org, ezPAARSE [1] s’est rapidement trouvé utilisé non seulement dans les établissements de l’enseignement supérieur et de la recherche (ESR) en France mais aussi à l’international, Etats-Unis en tête. Le principe en est relativement simple : un établissement qui utilise un reverse-proxy [2] pour donner accès aux ressources numériques (payantes) à ses lecteurs dispose de fichiers de logs qu’il peut alors analyser pour en tirer des informations du type “qui accède à quoi”. Utilisant le même principe que celui que la plupart des plateformes des fournisseurs et éditeurs utilise pour fournir des données d’usage COUNTER, ezPAARSE se place ici à un endroit qui permet de collecter des données très précises à la fois sur les ressources consultées (on peut souvent aller plus loin que le seul titre de la revue) et sur les catégories d’usagers propres à chaque établissement. Certains établissements ont décidé d’utiliser ce dispositif pour tous les accès à la documentation numérique et ne déclarent donc plus qu’une seule adresse IP aux éditeurs : celle de leur reverse-proxy. Et ce point de passage unique leur permet d’avoir une vue “complète” en terme de statistiques d’usage.
Le “qui” dont il est question ici pourrait techniquement désigner l’usager identifié individuellement mais, dans la pratique, cela ne sera pas le cas. Il s’agit de qualifier chaque action quantifiable se déroulant sur la plate-forme, avec des informations de statut (est-ce un étudiant, un chercheur…?), d’affiliation (est-ce quelqu’un de l’UFR Lettres, de l’école d’ingénieurs X…?) tout en préservant l’anonymat des personnes, la confidentialité des consultations et, d’une manière générale, l’ensemble des règles de la RGPD actuellement en vigueur.
Capacités de reconnaissance : travail partagé et obstacles
Ce qui permet à ezPAARSE de donner des informations sur les ressources consultées (le “quoi”), ce sont les analyses des plateformes éditeurs conduites de façon décentralisée et collaborative dans l’outil AnalogIST [3]. Les collègues en établissements peuvent venir participer à ce travail et voir leurs analyses transformées en parseurs (il y a une analyse par plateforme, ce qui correspond à un parseur) qui deviennent instantanément disponibles pour toutes les installations d’ezPAARSE. La couverture d’ezPAARSE grandit donc de façon continue[4] et cette progression n’est empêchée que dans un cas précis : celui des plateformes, heureusement relativement rares, qui proposent des URLs d’accès à leurs contenus non explicites. La plateforme EbscoHost en est l’exemple le plus ennuyeux. Dans cette situation, l’éditeur est prévenu et tout le monde croise les doigts pour qu’au moment de la refonte suivante de la plateforme concernée, la demande d’obtenir des URLs “lisibles” aboutisse.

- (A) https://ra21.org/
- (B) https://groups.niso.org/apps/group_public/download.php/21376/NISO_RP-27-2019_RA21_Identity_Discovery_and_Persistence-public_comment.pdf
- (C) https://www.arl.org/news/arl-comments-on-ra21-proposal-for-access-to-licensed-information-resources/
- (D) https://www.nicolasmorin.com/blog/ra21/
Qualification des usages : dépend des données locales
Les établissements qui utilisent un reverse-proxy peuvent aussi venir enrichir les traces de passages collectées en récupérant dans leurs annuaires les données catégorielles associées à chaque lecteur : niveau d’étude, filière, diplôme qu’elle prépare, équipe de recherche, laboratoire de rattachement, discipline, etc. Une fois cette opération conduite, les données à caractère personnel peuvent être tranquillement supprimées car elles ne sont plus utiles.
Les possibilités d’analyses deviennent alors extrêmement intéressantes : c’est le “qui” (au sens de “catégorie” plutôt qu’au sens de “personne” donc) qui se trouve désormais accessible ! Ces données, considérées comme sensibles et précieuses, ne sont pas fournies par les éditeurs dans l’environnement technique actuel.
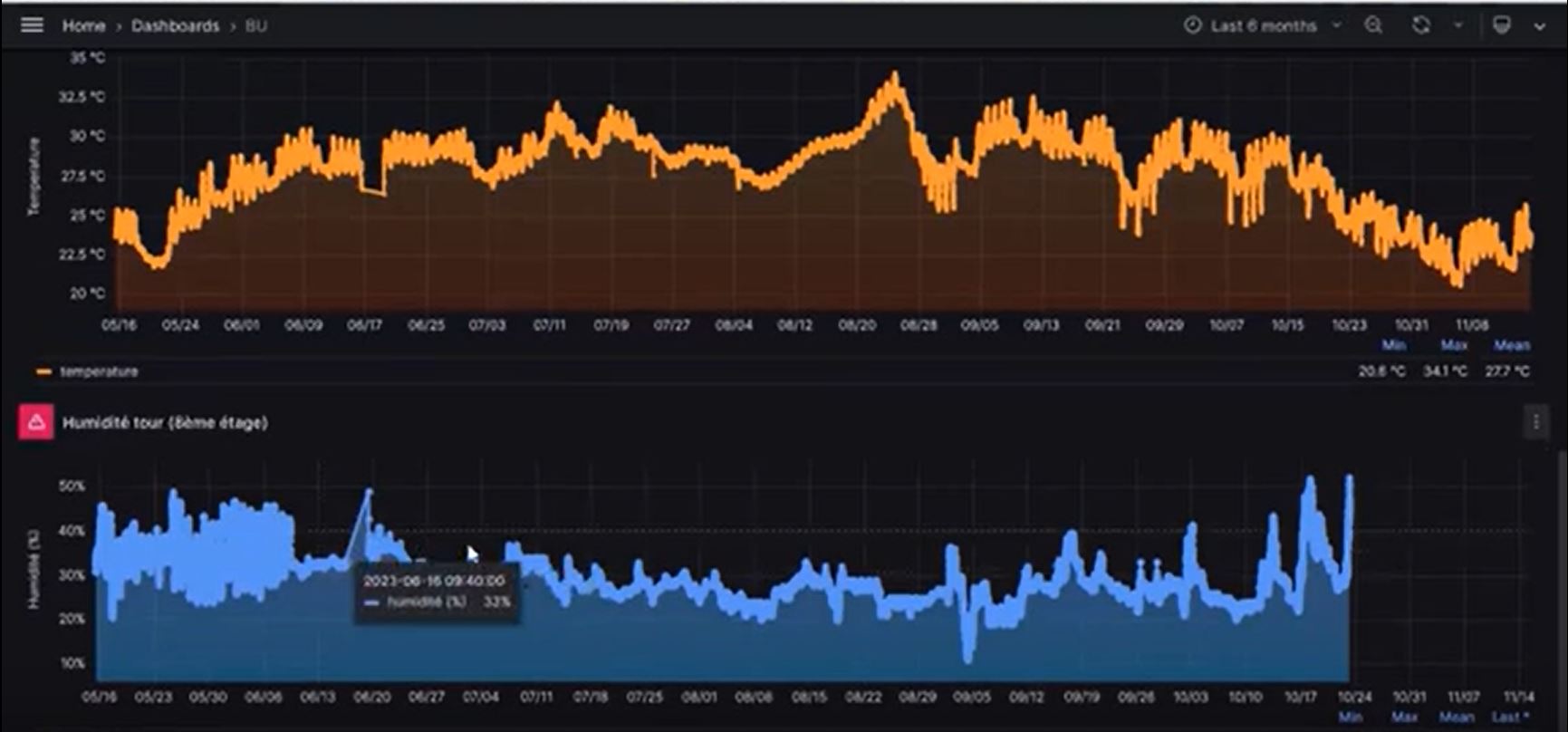
Les événements de consultation (ECs) produits par ezPAARSE peuvent alors être reversés dans ezMESURE [5] l’entrepôt national qui accueille les données reversées par les établissements de l’ESR français membres du consortium. ezMESURE est tout à la fois un lieu d’archivage, un moteur d’indexation et un outil de représentation graphique des données versées : chaque établissement accède à ses données sous la forme d’un ou plusieurs tableaux de bord. Voir ci dessous un exemple de tableau de bord obtenu dans ezMESURE à partir de données qualifiées (U. de Lorraine)
En outre, ce sont des données homogènes qui se trouvent hébergées par ezMESURE car elles sont toutes produites par des installations locales d’ezPAARSE. Cela permet d’envisager des tableaux de bord communs que tous les établissements peuvent mettre en œuvre sur leurs données propres pour proposer des calculs d’indicateurs partagés : pour des ressources particulières, pour des zones géographiques, pour des établissements de même nature, etc.
Ainsi, une preuve de concept a été récemment conduite avec le SICD de Montpellier sur la confection d’un tableau de bord contenant directement les indicateurs utiles au renseignement de l’ESGBU.
C’est un premier pas sur un autre projet, plus ambitieux, de mise en commun d’un sous-ensemble de données croisées entre établissements : pour travailler sur une ressource documentaire commune, une discipline particulière, des publics spécifiques mais qu’on retrouve dans plusieurs établissements, etc. Des premiers essais de tableaux de bord devraient être disponibles pour octobre 2019, les premiers essais ayant démarré avec les Universités de Lille et de Lorraine.
COUNTER 5 : let’s roll
Sortie en juillet 2017 pour une obligation de compatibilité côté éditeur en janvier 2019, la nouvelle version du Code COUNTER modifie en profondeur la nature et la forme des rapports. Elle diffère également des précédentes en ce qu’elle passe le Code en mode de révision continue (“rolling release”) plutôt que les sorties de nouvelles versions majeures tous les 4 à 5 ans.
Une remise à plat complète de la présentation des rapports a été opérée. Alors que les versions 1 à 4 décrivaient un certain nombre de rapports spécialisés la version 5 possède quatre “rapports maîtres” positionnés plutôt sur une échelle de granularité du comptage.
On distingue ainsi le Platform Report (rapport maître de plate-forme), suivi du Database Report (rapport sur les bases de données éventuellement hébergés sur la plate-forme), du Title Report (rapport sur les titres de livres ou de revues) et enfin de l’Item report (rapport sur les éléments individuels). Chaque rapport propose des “vues standard” regroupant les chiffres et cas d’usage les plus courants ; et une interface permettant de générer un rapport à la demande selon un certain nombre de paramètres (ce qui, dans le cas de l’Item report par exemple, peut rapidement produire des fichiers de taille considérable…).
La caractérisation des contenus (open access ou non, chapitre ou livre, année de publication…) est désormais opérée au moyen d’attributs pouvant chacun prendre un nombre limité de valeurs. Par exemple, l’attribut access_type peut actuellement prendre les valeurs “OA_Gold” pour les éléments en accès ouvert en “voie dorée”, ou “Controlled” pour l’ensemble des autres contenus (une troisième valeur, “OA_Delayed”, devrait prochainement venir caractériser les contenus en accès gratuit après une période d’embargo). L’année de publication devient également un attribut (YOP pour Year of Publication), mettant fin à la présentation peu commode du JR5.
Ceci met un terme à un certain nombre des limitations relevées plus haut, le prix à payer n’étant que la maîtrise d’un outil de manipulation de données. Ainsi, il est possible en activant à la fois la variable “Access_type” (permettant de distinguer accès payant et Open Access Gold) et l’année de publication, d’obtenir des chiffres sur le pourcentage d’articles en OA téléchargés sur les trois dernières années de publication, ce qui était auparavant impossible. De même, il devient possible d’obtenir un rapport unique et cohérent centralisant l’ensemble de l’usage des ebooks.
Du fait de la présentation intégralement en colonnes et attributs, l’intégration dans des outils de visualisation dédiés de type Tableau, Omniscope ou Kibana devrait également être facilitée.
Le travail important d’adaptation et d’implémentation demandé côté éditeur (du fait notamment de l’interface de demande de rapports personnalisés) a retardé un peu le calendrier d’implémentation [6] . On peut espérer qu’une partie de ce retard sera amortie par la mise en conformité des plates-formes techniques multi-éditeurs telles Atypon ou Highwire. L’intégrité des données ne sera dans tous les cas pas en cause, puisque tout l’usage depuis janvier 2019 doit être rendu disponible en COUNTER 5, en téléchargement direct comme par moissonnage SUSHI.
Évolutions futures
Depuis la fin 2012, le portail Mesure [7] est le portail consortial de moisson SUSHI des rapports COUNTER pour les périodiques (JR1 et JR1a) et à la norme COUNTER 4 uniquement. En grande partie clone du JUSP [8], projet anglo-saxon mené par le JISC, il n’en a par contre jamais atteint la même amplitude : seuls les rapports de 13 éditeurs sont moissonnés semestriellement, contre plus de 90 mensuellement côté JUSP.
Malgré ces limites, évidentes, l’outil aura démontré qu’on peut économiser la moisson manuelle pour un certain nombre de rapports et d’éditeurs, archiver les données pour permettre des analyses rétrospectives et proposer des vues “standard” des données moissonnées. En outre, il aura servi d’argument pour faire connaitre la norme COUNTER à des éditeurs qui ne la connaissaient pas ou trop peu et faire valoir le besoin pour les établissements clients de disposer à la fois de données normées et d’un moyen de les récupérer au moins semi-automatiquement.
L’idée d’économiser la moisson manuelle à ses membres reste pourtant d’actualité pour le consortium Couperin.org et le passage global à la norme COUNTER 5 permet d’envisager à la fois un nouvel outil et une nouvelle dynamique : CC-PLUS, le logiciel libre et l’interaction possible avec un outil de gestion consortiale comme ConsortiaManager.
Projet lancé par l’ICOLC et coordonné par Jill Morris / PALCI depuis 2017, CC-PLUS [9] a d’abord bénéficié d’une bourse d’un an [10] pour créer un prototype dans lequel différents consortiums participants ont pu déclarer des établissements membres, des informations d’identification SUSHI et procéder à des premières moissons. Le code source du prototype, sous licence libre a été versé sur la célèbre forge logicielle GitHub [11].
Une deuxième phase, soutenue par un nouveau financement de deux ans, a débuté en octobre 2018. Une équipe technique plus complète (un développeur principal, une coordinatrice de projet et une UX designer ont été embauchés) a cette fois été mise en place qui se donne pour objectifs de proposer “une plate-forme open source permettant aux consortiums du monde entier de gérer les données d’utilisation de leurs bibliothèques via une interface unique, d’automatiser leur collecte de données et de prendre des décisions en connaissance de cause concernant leurs investissements en ressources électroniques”. Le consortium Couperin.org participe à cet effort.
La plateforme produite pourra être accessible sous la forme d’une instance commune partagée et hébergée dans le cloud ou bien être hébergée localement par chaque consortium qui le souhaite.
Des partenariats avec des opérateurs privés seront possibles pour assurer l’analyse des données ainsi récoltées dans des outils tiers commerciaux par le biais d’une API qui reste à spécifier.
Pour une plate-forme statistique nationale
Pour valoriser et centraliser toutes ces évolutions, la question se pose à nouveau d’une plateforme nationale, qui pourrait être portée par Couperin, capable de présenter à un niveau (au minimum) général et agrégé, des chiffres issus de l’ensemble des outils évoqués dans cet article. Au niveau fonctionnel, le GTI a déjà travaillé sur cette question et produit une “Vision du produit” synthétique (soit un document listant les fonctionnalités minimales attendues) selon deux scénarios possibles.
Ce projet devrait reprendre un peu de souffle à la faveur de l’adoption par Couperin d’un outil de gestion consortiale, ConsortiaManager à l’horizon de l’été 2019 ; non pas tellement en raison de la présence dans cet outil d’un module statistique [12] mais du fait de la possibilité de concentrer dans un outil unique des données jusqu’à présent réparties dans des outils et services distincts.
Ce dossier sera remis en route à compter de cette rentrée universitaire 2019.
[1] https://www.ezpaarse.org
[2] http://bibliopedia.fr/w/index.php?title=EZproxy
[3] https://analyses.ezpaarse.org
[4] Tous les parseurs existants sont exposés sur https://github.com/ezpaarse-project/ezpaarse-platforms/ (il y en a actuellement 225)
[5] https://ezmesure.couperin.org/
[6] La page https://www.projectcounter.org/about/organisations-working-towards-release-5-compliance/ recense les éditeurs en cours d’implémentation.
[7] https://www.couperin.org/services-et-prospective/statistiques-dusage/mesure
[8] https://jusp.jisc.ac.uk/
[9] http://www.palci.org/cc-plus-overview/
[10] “IMLS National Leadership Grant“ pour la période juin 2017 – mai 2018
[11] https://github.com/lsr2912/CC-Plus
[12] qui reste à tester et expertiser dans une version compatible à COUNTER 5, ce qui n’est pas le cas actuellement